Data Structure Notes
Tree
分成Full/Complete/Perfect/Skewed四種
- Full代表每一個node都有0或2個children
- Complete代表d-1 level都是滿的
- Perfect代表所有node都有2個children
- Skewed代表所有node都只有一個children(非常unbalanced)
結構如下,正常的complete binary tree用array不會浪費,但如果是skewed就超浪費,所以可以用pointer
1 |
|
Max Heap
是一種binary tree結構,root一定會比leaf還要大,只要符合這個結構就是max-heap
適合用在實現Priority Queue資料結構以及HeapSort演算法
Priority Queue
需要滿足四種不同的operation
- INSERT(S,x): 把key x插入到S集合
- MAXIMUM(S): return集合中最大的key
- EXTRACT-MAX(S): return & remove集合中最大的key
- INCREASE-KEY(S, x, k): 將x的key增加到k
| Operation | Heap Method | Array Method在sorted array下(很花時間) |
|---|---|---|
| INSERT | $O(lgn)$: 直接插在最後並做fix heap的動作 | $O(n)$: 每一個要往後 |
| MAXIMUM | $O(1)$: 直接read第一個 | $O(1)$: 直接read第一個 |
| EXTRACT-MAX | $O(lgn)$: 直接刪除第一個元素並用最後一個取代再做heapify | $O(n)$: 每一個要往後 |
| INCREASE-KEY | $O(lgn)$: 從target遍歷一個適當的地方插入新的key | $O(n)$: 每一個要往前 |
Disjoint Set
用來快速判斷 兩個元素是不是在同一個集合,以及把 兩個集合合併。
Terminology
- Set:集合,$S_1,S_2,…,S_k$
- Collection: a family of sets,$S={S_1,…,S_k}$
- Representative: 一個set中類似班長的角色,也判斷兩個集合是不是有關聯就要看他們的representative是不是一樣的
支援的操作
- Make-Set(x): S_x={x}$,把某一個元素自成一個集合
- Union(x,y): $S_x\cup S_y$
- Find-Set(x): 找有含x的集合的班長是誰
Example
<img src=/assets/posts/Algorithm/DISJOINT-SET-EXAMPLE.jpg” alt=”” width=300>
用Linked-List實作
<img src=/assets/posts/Algorithm/DISJOINT-SET-Implement.jpg” alt=”” width=300>
從例子的說明可以知道Make-Set和Find-Set的time都是constant,但要union的話,串起來本身沒問題,要改後面的element的representative會很麻煩,有幾個要改幾次
Time $O(m+n^2)$
- $n$: 代表Make-Set操作的數量
- $m$: 代表Make-Set, Find-Set, Union操作的總數量
- Make-Set: $O(n)$
- Find-Set: $O(1)$
- Union: $\sum\limits_{i=1}^{n-1}i=O(n^2)$
| Operation | # of objecs updatd |
|---|---|
| MAKE-SET(x_1) | 1 |
| MAKE-SET(x_2) | 1 |
| . . . |
. . . |
| MAKE-SET(x_n) | 1 |
| UNION(x_2,x_1) | 1 |
| UNION(x_3,x_2) | 2 |
| UNION(x_4,x_3) | 3 |
| . . . |
. . . |
| UNION(x_n,x_{n-1}) | n-1 |
Weighted-union Heuristic(改善上面的問題)
短的掛到長的,要改representative的數量就會比較少
- Time: $O(m+nlgn)$
用Forest的方式實作
也就是用root tree的方式表示
- Make-Set: 創一個只有一個node的tree
- Find-Set: 就是之前提過的找path,找班長就是找root
- Union: 把其中一個root指向另一個root
Speed Up技巧
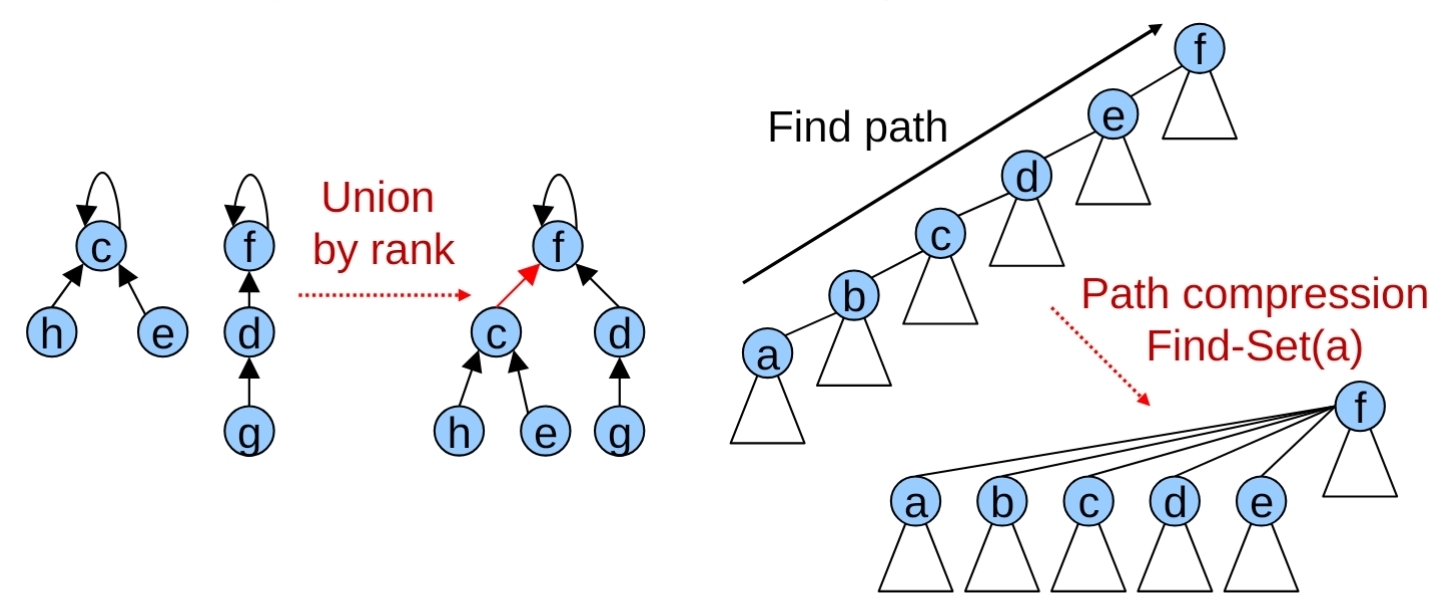
- Union by rank:就是前面提到的短的掛到長的概念,在forest的結構,是把高度(depth)比較少的串到比較大的,複雜度才不會變高
- Path Compression: 在find path 的過程中,直接更改途中經過的那些node的representative
1 |
|
1 |
|
Graph
Terminology
- Sparse: $\mid E\mid=O(\mid V\mid)$
- Dense: $\mid E\mid=O({\mid V\mid}^2)$
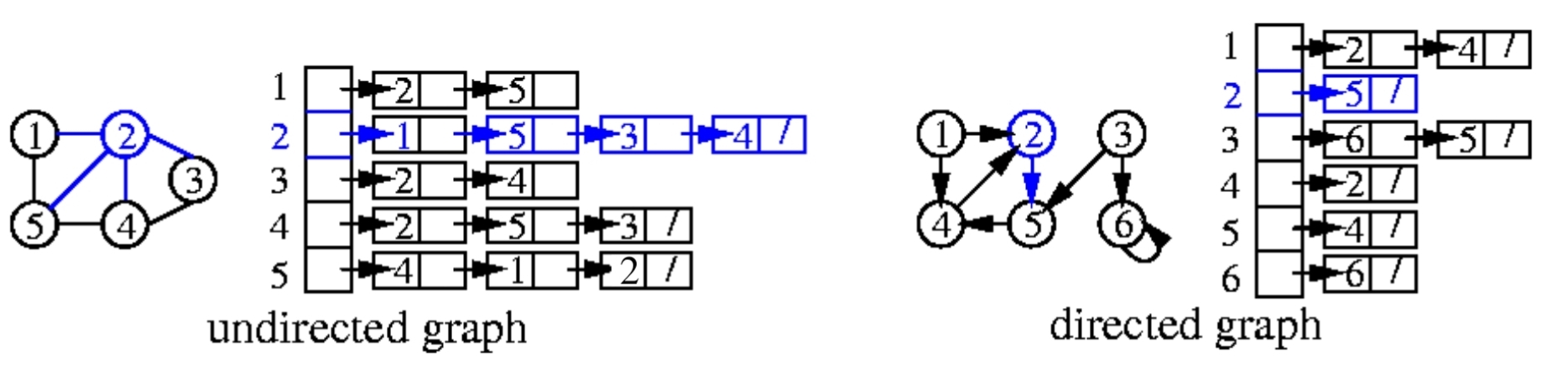
Adjacency List
專門用來記錄Graph中,點之間的關係,用類似linked-list的方式
- 優點: 利用$O(V+E)$的空間,適合儲存sparse graph(密度較低)
- 缺點: 找edge必須要traverse list
Adjacency Matrix
大小$\mid V\mid\times \mid V\mid$的矩陣,有edge就儲存1
- 優點: 找edge的複雜度$O(1)$
- 缺點: $O(V^2)$的儲存空間
| List | Matrix | |
|---|---|---|
| 快速找到edge | ✅ | |
| 快速找到Vertex Degree | ✅ | |
| Traverse Graph速度 | $O(V+E)$ | $O(V^2)$ |
| Sparse Graph Storage | $O(V+E)$ | $O(V^2)$ |
| Dense Graph Storage | ✅ | |
| 插入/刪除Edge | ✅ | |
| 適合大多數應用 | ✅ |